
팀엘리시움에서는 작년부터 Prisma를 도입해 사용하고 있습니다. 체형 불균형 문제 해결을 위한 프로젝트 POMS에서도 역시 Prisma를 사용했는데, 이 프로젝트를 진행하면서 경험한 성능 이슈에 대해 이야기해 보려 합니다.
페이지가 안 떠요
어드민 페이지의 학교 페이지에서 학생 목록이 뜨는 속도가 매우 느리다는 버그가 접수되었습니다. 실제로 접속하니 1분(!) 이상 로딩이 지속된 후에야 학생 목록이 로드되었고, 빠르게 처리해야 하는 업무 특성상 유저 불편함이 심각한 상황이었습니다.
POMS 어드민에서 각 학교 페이지는 아래와 같은 과정을 통해 불러오고 있습니다. 학교 페이지에 접속하면 서버로 학생 데이터를 요청하고, 현재 검수해야 하는 검수 대상 측정 데이터를 서버에서 조회/파싱 해 응답하는 형태인데, 파싱은 시간이 오래 걸리는 작업이 아니기 때문에 DB의 측정 데이터를 조회하는 부분에서 문제가 생겼을 거라 추측했습니다.
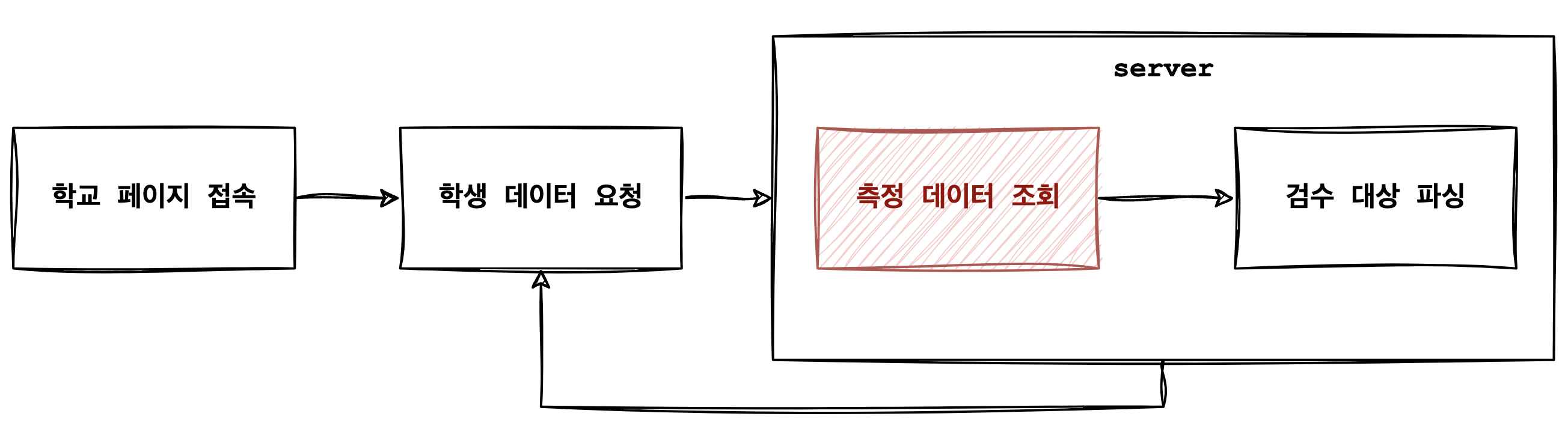
왜 이렇게 느리지?
POMS의 데이터는 다음과 같은 구조를 가지고 있습니다. 측정 데이터는 학생을, 학생은 학교를 참조하고 있는 형태입니다.
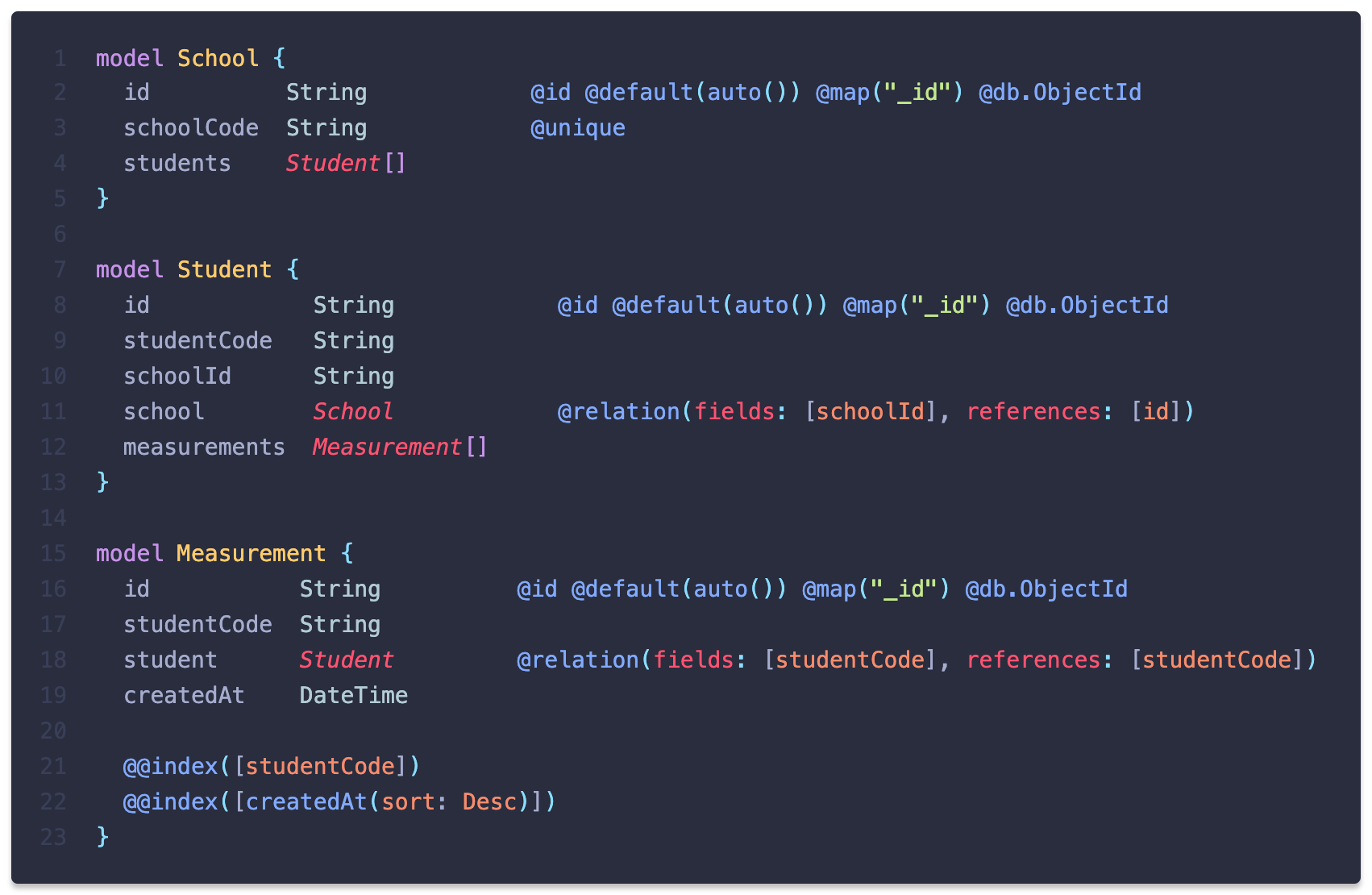
이 구조에서 특정 학교 모든 학생의 데이터를 불러오기 위해 다음과 같은 query를 작성했습니다.
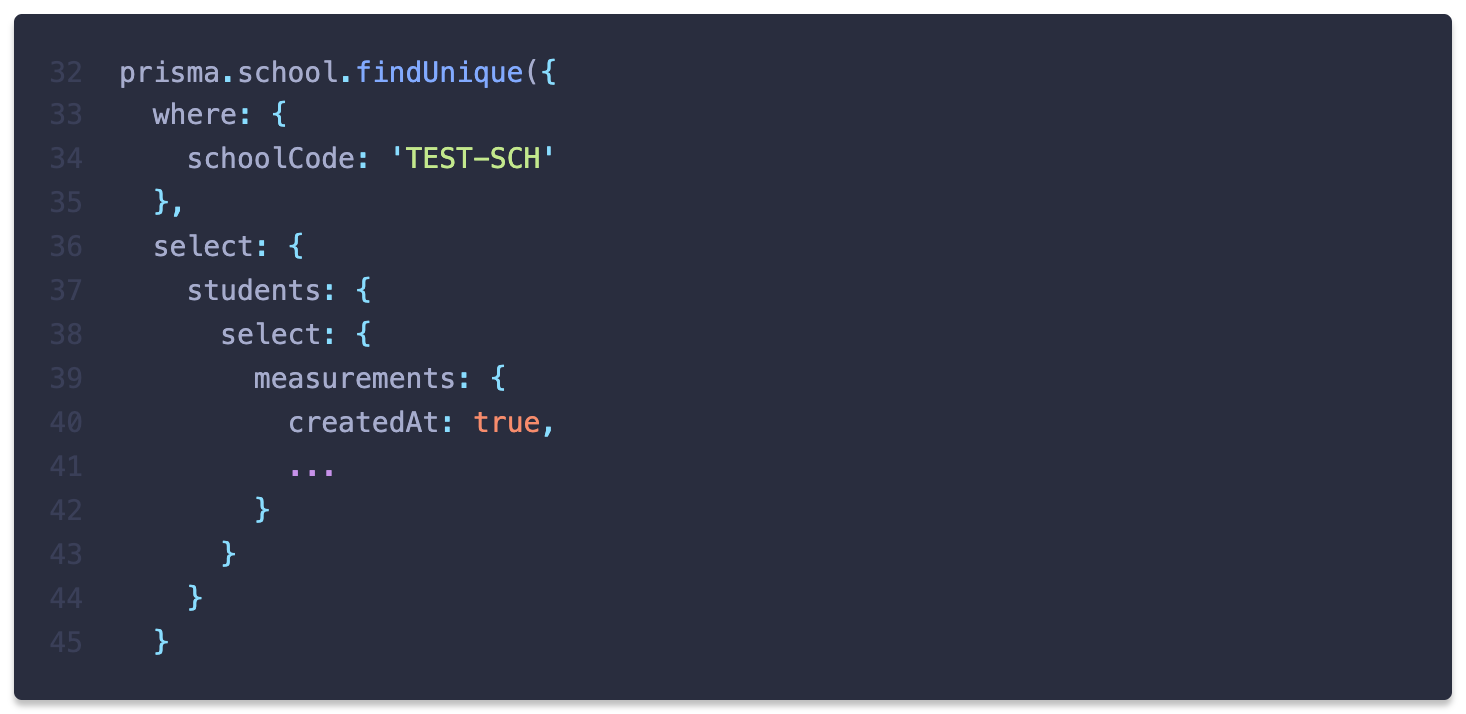
이 query를 작성하면서 기대한 것은 인덱스를 통해 학생을 필터링하고 해당하는 측정 데이터를 반환하는 것인데, Prisma가 실제로 작성한 raw query를 통해 아래의 문제점들을 확인할 수 있습니다.
- 모든 query를 aggregation으로 작성
- 불필요하게 중첩된 구조
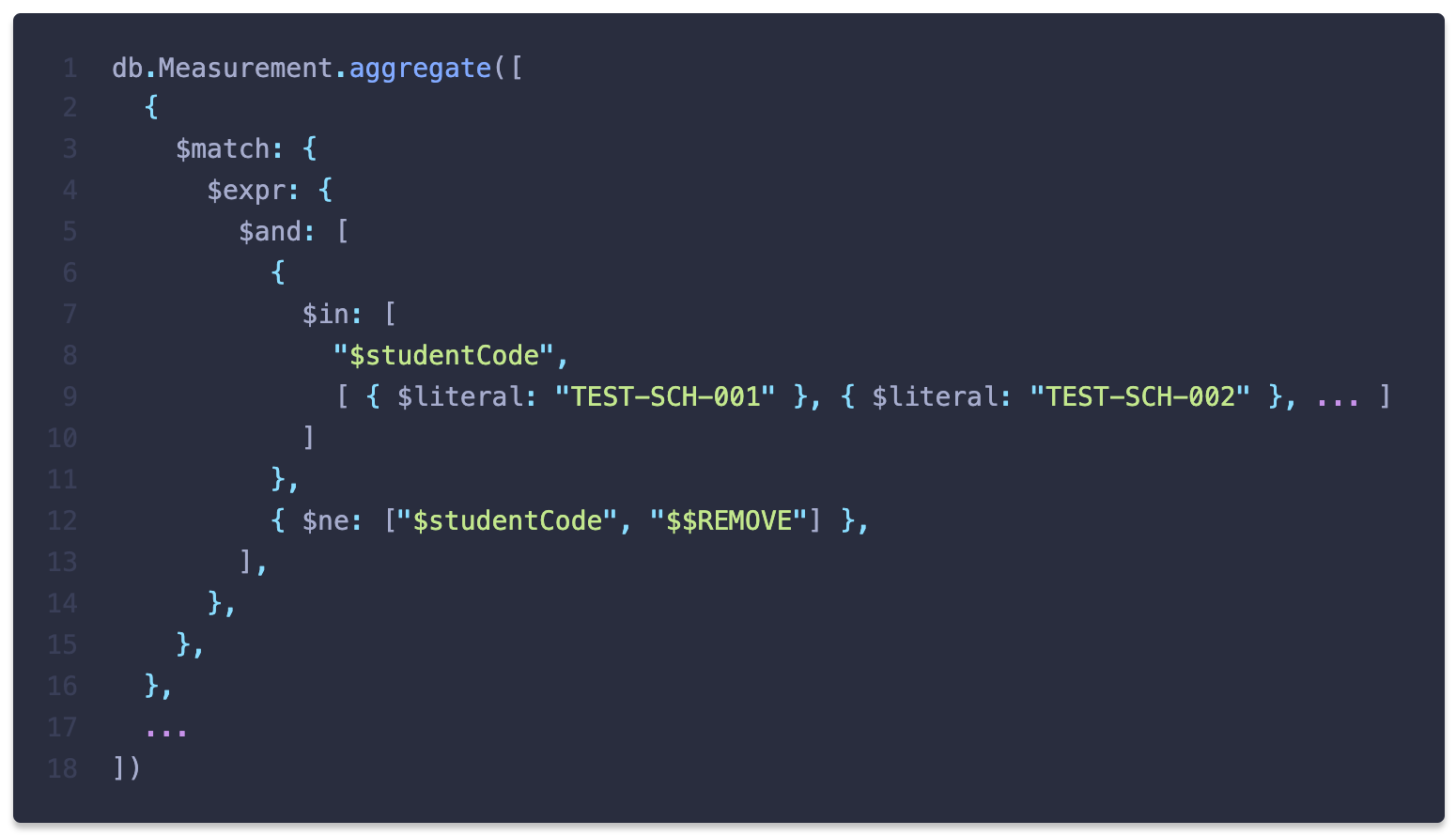
- 인덱스를 사용할 수 없는 query 형태:
$expr에서의$in사용
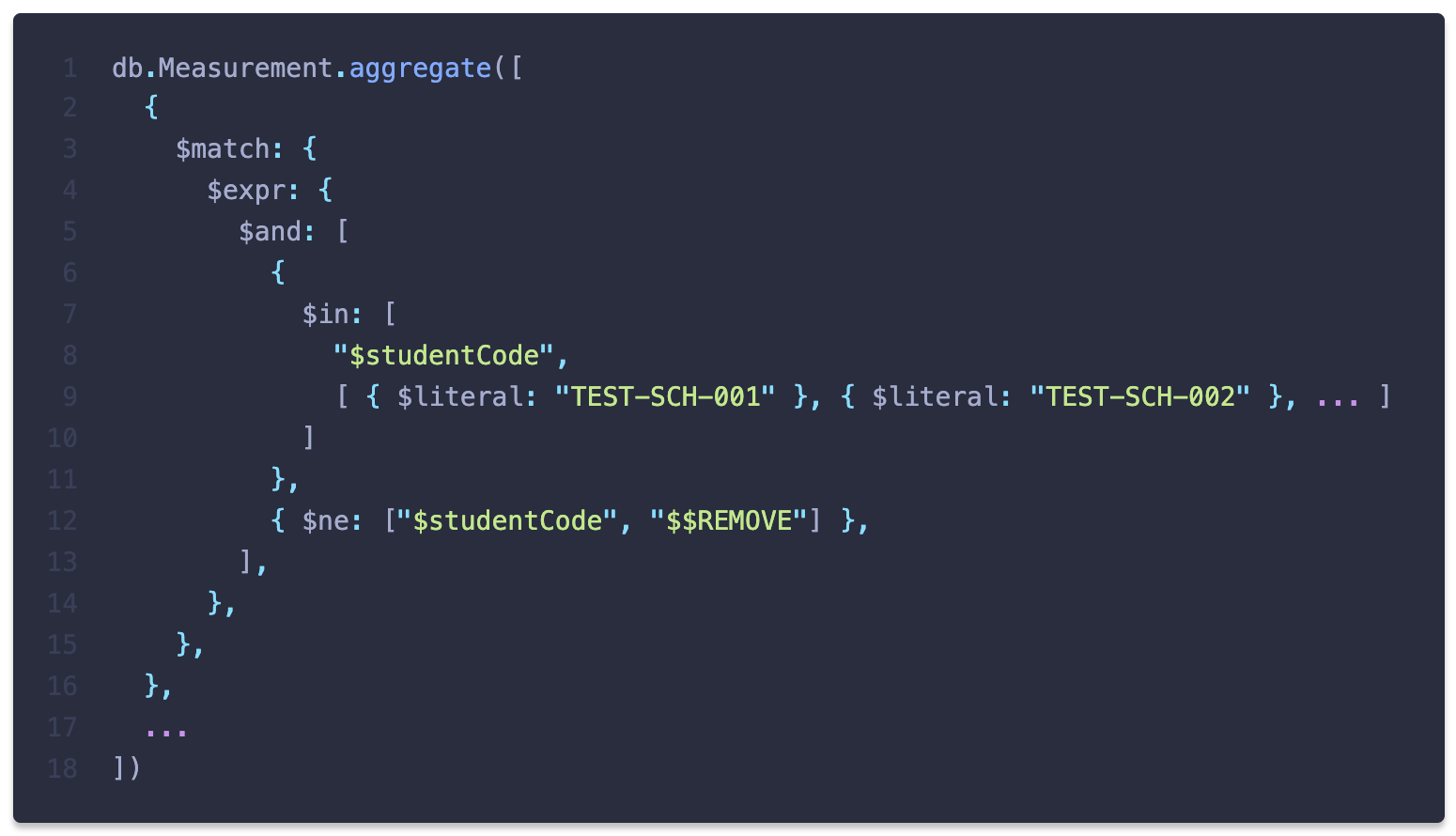
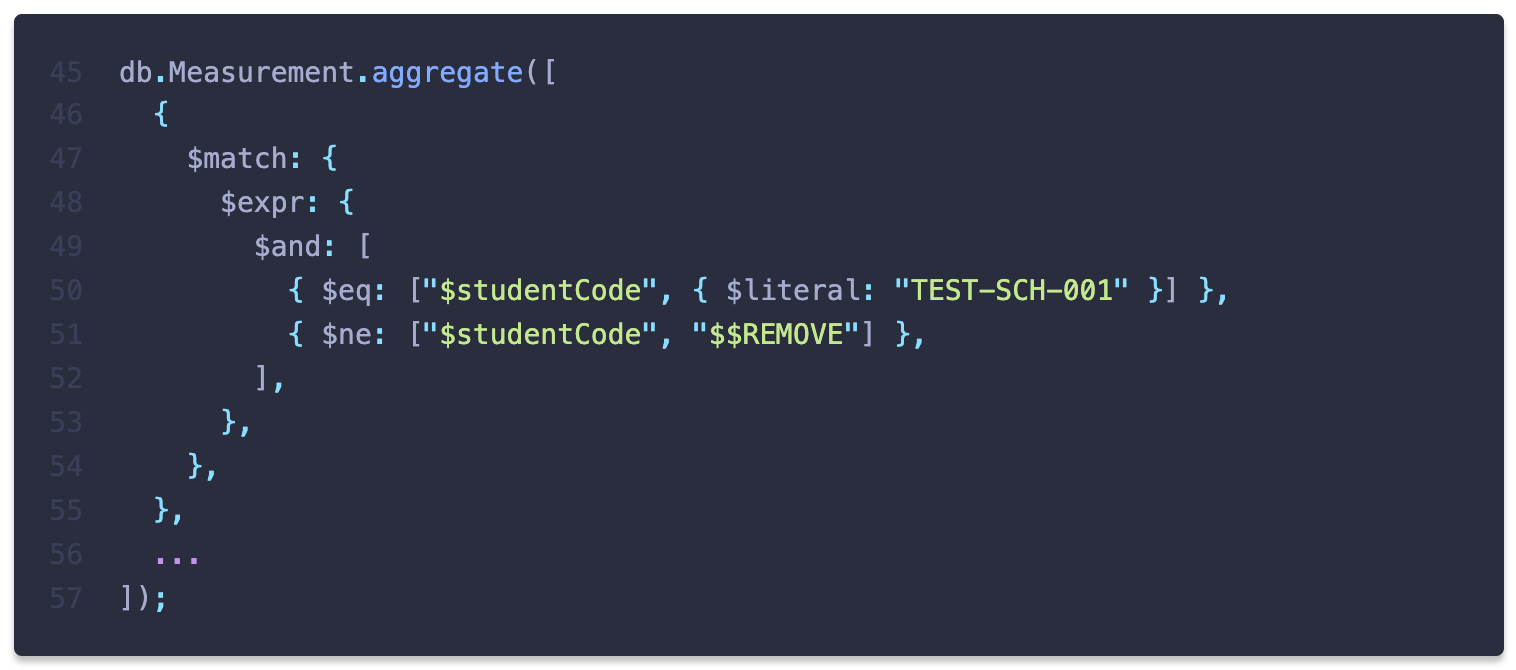
여기에서 로딩 문제를 유발한 것은 바로
$in이었습니다. MongoDB aggregation의 $expr에서 인덱스를 사용할 수 있는 표현식은 $eq, $lt, $lte, $gt, $gte에 한하는데 $in 이 사용된 것입니다. 아래와 같이 실행계획을 통해 인덱스를 사용하지 않고 컬렉션 전체를 탐색(COLLSCAN)했다는 사실을 확인할 수 있습니다. 
어떻게 해결해야 하지?
하지만 이 raw query는 Prisma 엔진이 생성한 것이기 때문에, 개입이 까다로운 상황입니다. Prisma github에도 이러한 문제점이 보고되어 있었으나 특기할 만한 해결책은 보이지 않았기 때문에, 데이터 조회 방식을 변경하기로 했습니다.
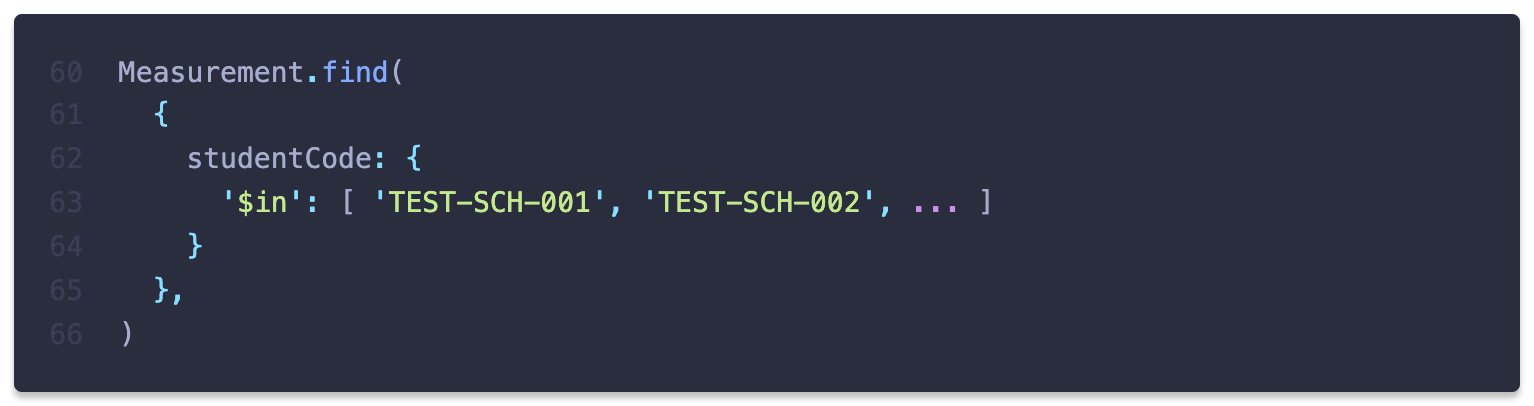
모든 학생들의 측정 데이터를 하나의 query로 조회하는 대신 특정 학생의 측정 데이터만 조회하도록 수정하면 measurement collection에서 학생 코드와 일치하는 값을 탐색하기 위해
$eq을 사용하리라 기대했습니다. 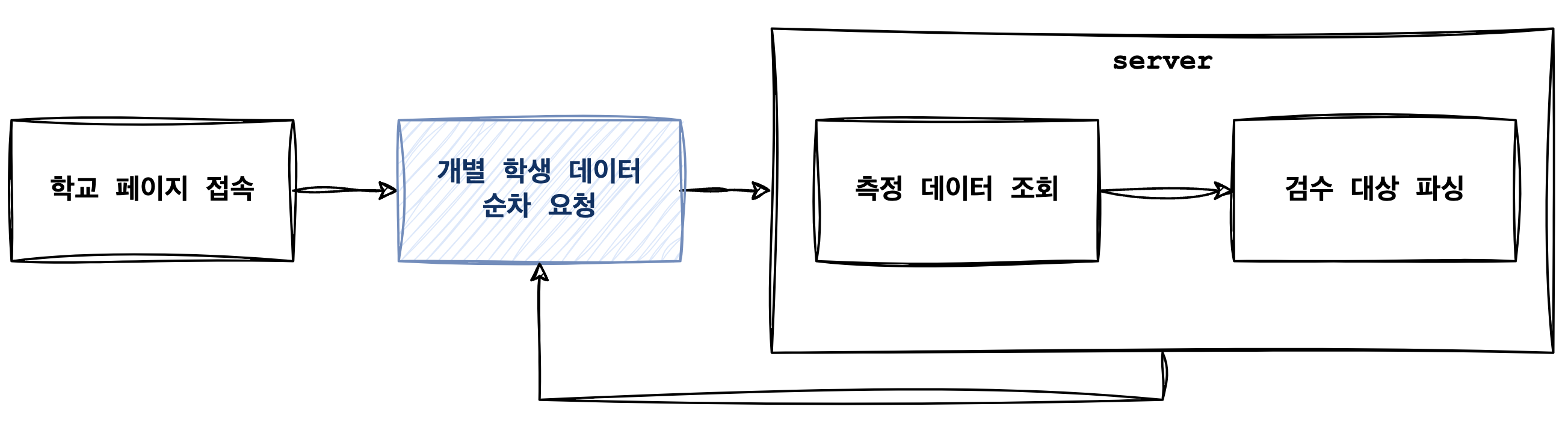
query를 수정하자 Prisma는 기대대로
$eq을 사용하는 raw query를 작성했습니다. 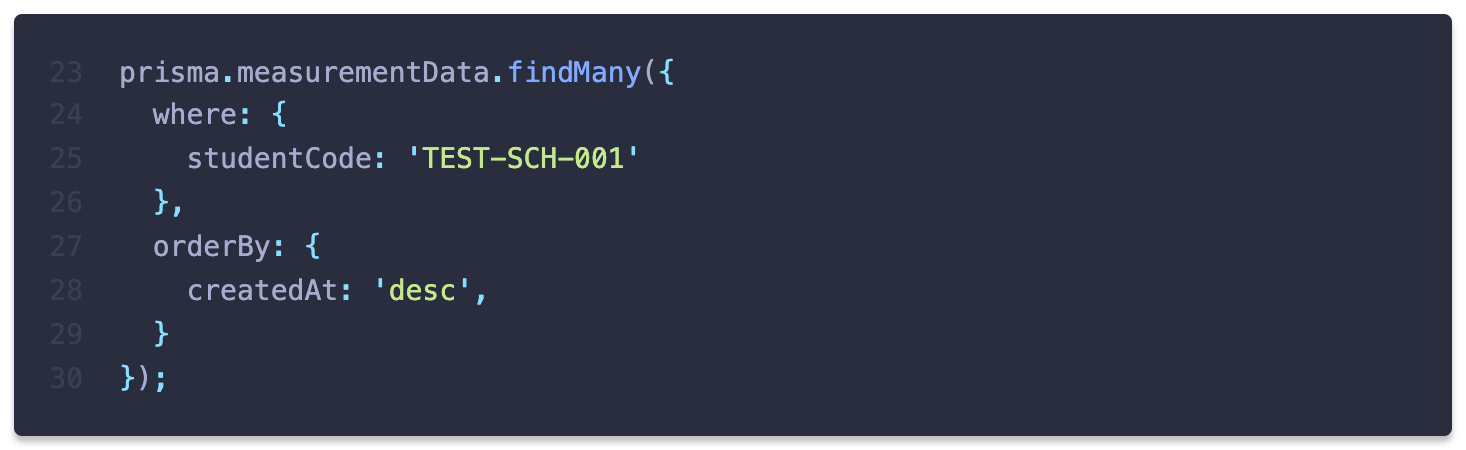
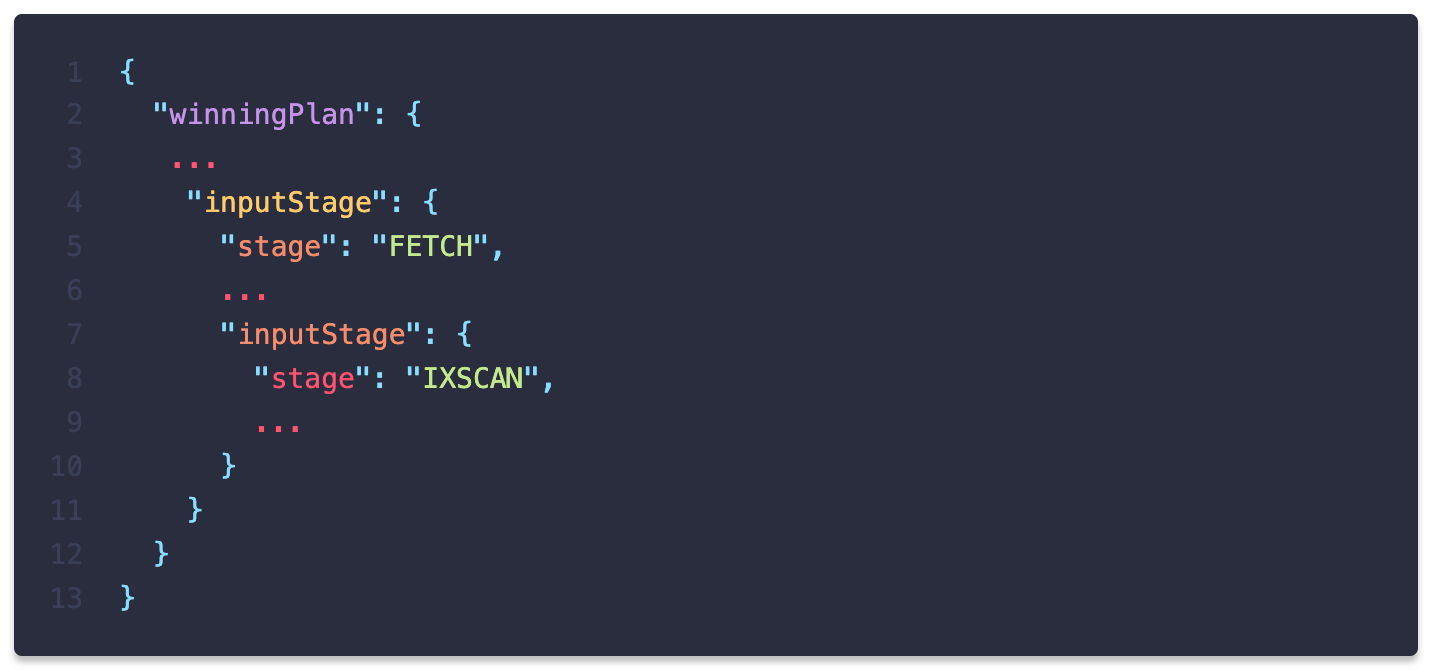
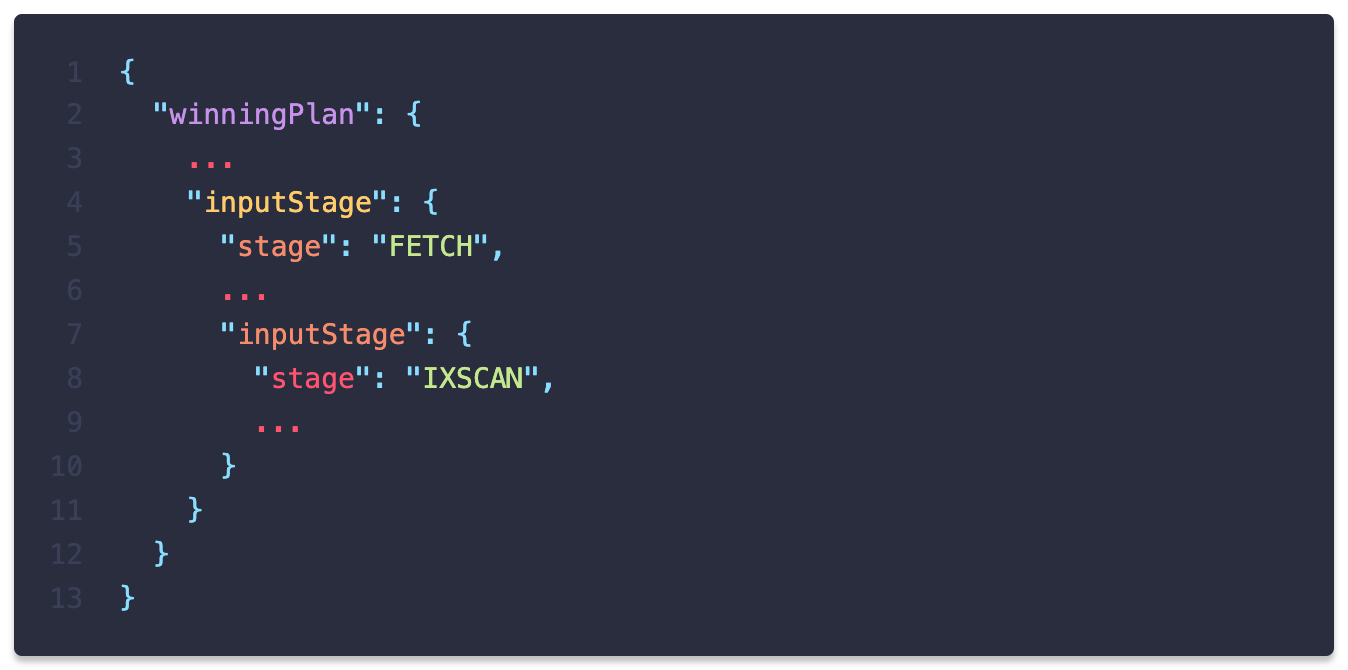
실행계획을 통해 인덱스 스캔(IXSCAN)으로 탐색한 것을 알 수 있습니다.
요청하는 query 수 자체는 증가했지만 실행 시간이 감소했기 때문에 로딩 시간 문제를 해결할 수 있었습니다. 그러나 기대했던 것과 다른 raw query로 유발된 문제를 맞닥뜨리자, 드러나지 않았을 뿐 다른 어플리케이션에서도 동일한 문제가 있는 건 아닐까? Prisma를 도입하려 했던 다른 프로젝트에서도 동일한 문제가 발생하지는 않을까? 우려되기도 했습니다.
ORM을 사용하는 이상 만날 수밖에 없는 문제라는 생각도 들었지만, 개발 편의 측면에서 ORM은 쉽게 포기하기 어려운 부분이기 때문에 Prisma 도입 전까지 사용하던 Mongoose는 어떻게 raw query를 작성하고 있는지 비교해 보기로 했습니다.
Mongoose vs Prisma
MongoDB에는 사실 relation이라는 개념이 없지만, Prisma에서는
@relation 데코레이터를 사용하여 관계를 명시하고 레이어를 형성할 수 있습니다. 마찬가지로, Mongoose에서도 ref와 virtual 메서드를 사용하여 문서 간의 관계를 명시할 수 있습니다. 스키마는 다음과 같은 모습이 됩니다.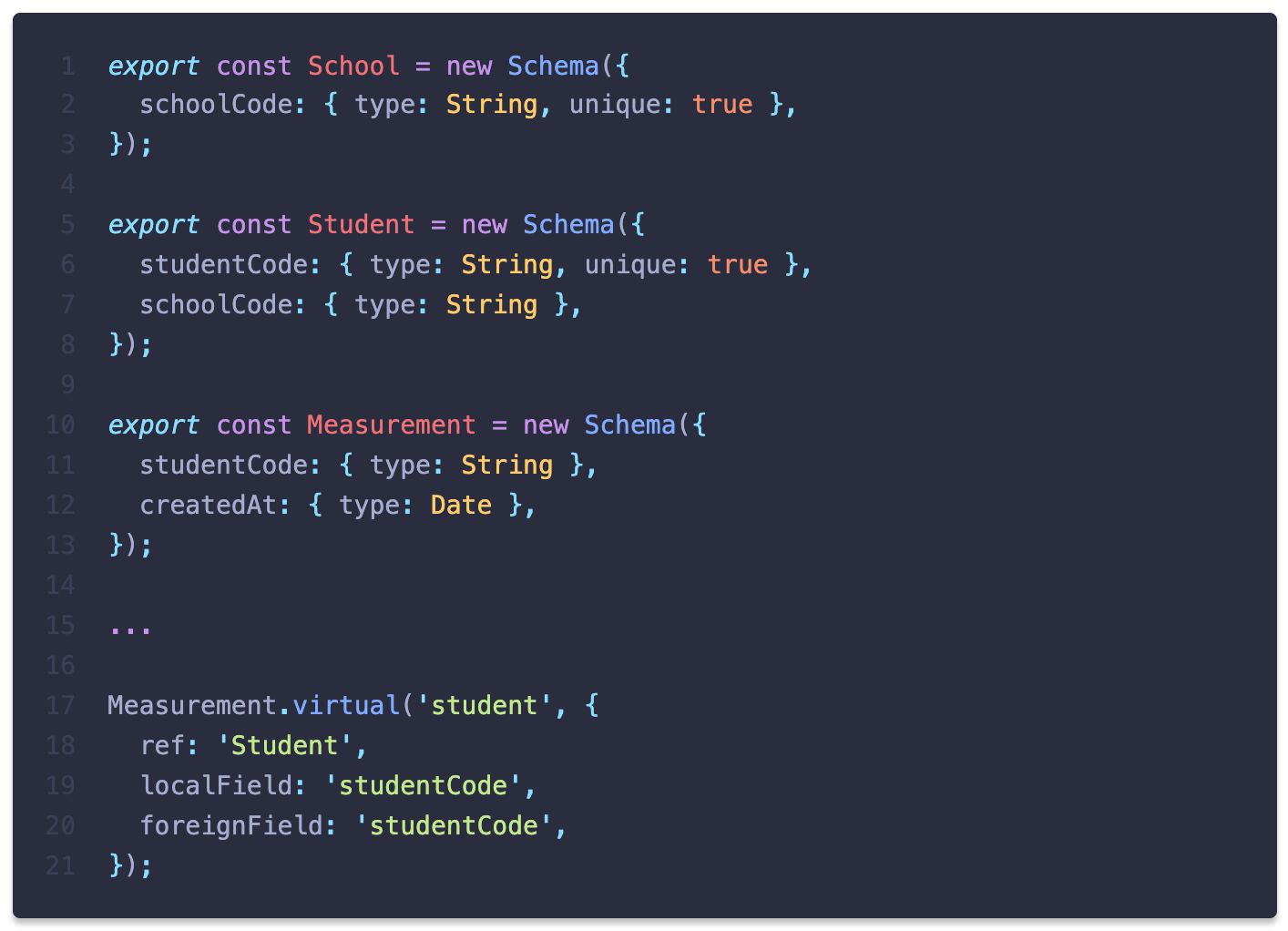
또한, Prisma에서 client를 통해 다른 컬렉션의 문서를 참조할 수 있는 것처럼 Mongoose에서는
populate 기능을 사용하여 ref로 명시한 다른 컬렉션의 문서를 참조할 수 있습니다. 이 기능을 사용해 Mongoose query를 작성하고, Mongooser가 어떤 raw query를 생성하는지 살펴보았습니다.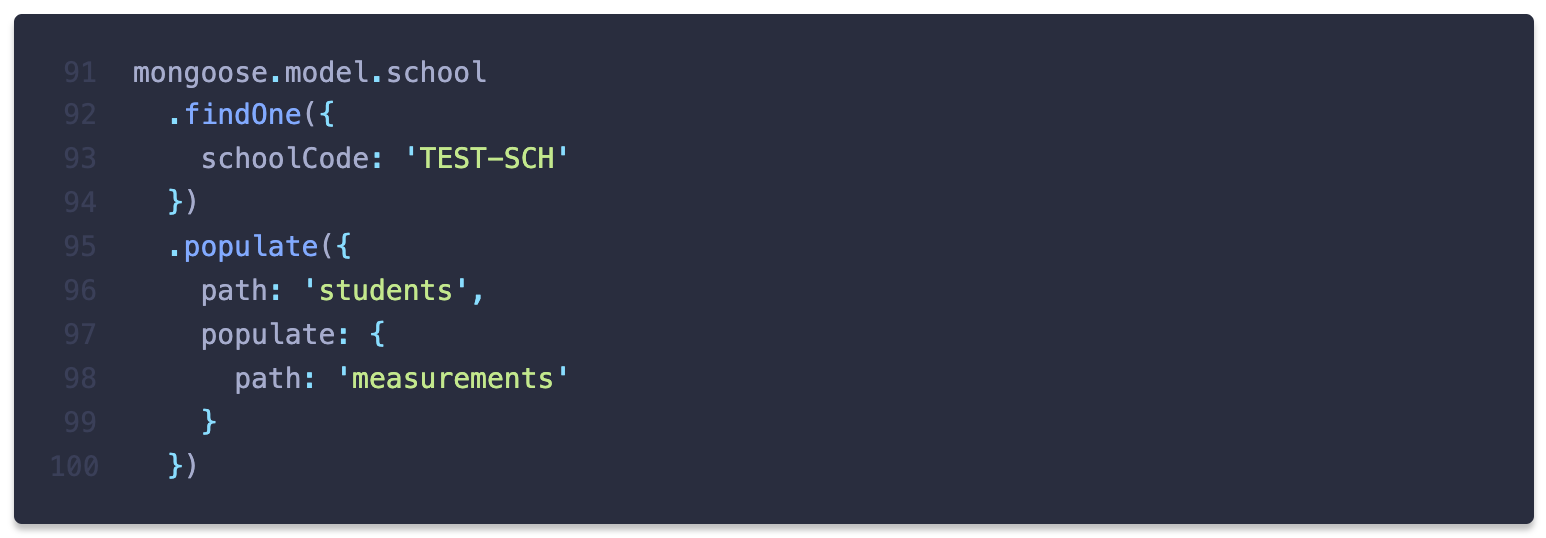
실제로 Mongoose가 작성한 raw query를 살펴보니 불필요한 aggregation을 사용하지도 않았을뿐더러 인덱스를 사용할 수 있도록 작성하고 있었습니다. Prisma가 작성한 raw query와 비교하면 차이점이 확연히 드러납니다.
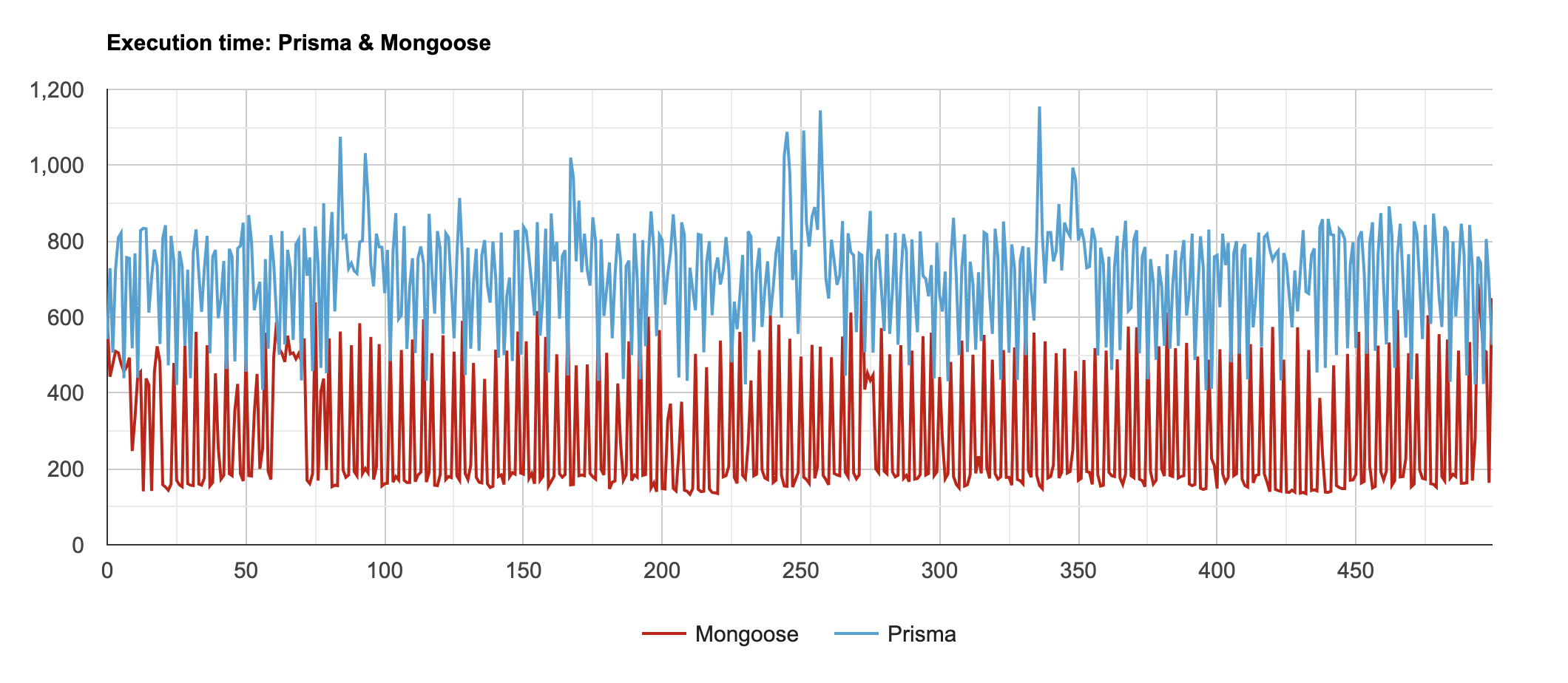
실행 계획을 통해 다음과 같이 IXSCAN이 명시된 모습도 살펴볼 수 있었습니다. 당연히, 실행 시간도 훨씬 짧았습니다.
결론
Mongoose와 Prisma에서 생성된 raw query와 실행 시간을 교차 비교하는 테스트를 통해 현재와 같은 데이터 구조에서는 Mongoose를 사용하는 것이 훨씬 유리하다는 결론에 도달했습니다.
이 과정을 통해 어떤 기술이든 도입하기 전 충분한 실사용 테스트를 거쳐 비교하고 검증해야 한다는 소중한 경험을 얻을 수 있었습니다. 테스트를 위해 두 가지 ORM(ODM) 스키마를 작성하고 데이터를 지속적으로 살펴보면서 용도에 적합한 데이터 모델링이 이루어진 것이 맞는지, ORM 사용의 Trade-off는 무엇인지에 대한 고민 역시 할 수 있었습니다.
지금은 이러한 경험을 바탕으로 데이터를 어떻게 모델링하면 좋을지, 어떤 기술을 사용해야 편의성과 성능 두 마리 토끼를 다 잡을 수 있을지 리서치하고 있습니다. 결국 어떤 기술을 선택하게 되었는지, 그 까닭은 무엇인지 또 알려드리도록 할게요. 팀엘리시움의 다음 프로젝트도 기대해 주세요! 👏
